Compression In Databases

A software engineer who is enthusiast about back-end engineering and system design with a flexible mindset. I love playing with frameworks and moving between the languages just like an artist playing
Introduction
It's well-known that the database's main bottleneck lies in I/O. That's what makes database designers aim toward reducing it in any possible way, one of them is to look carefully at the workload and choose the suitable storage model (for more info Storage Models for Databases). Another tool that is widely used in computer science, is to compress data before storing it and postpone decompression as long as we can (late materialization). However, DB should not lose any data in compression, which means that we get the same data that we inserted.
Compression Granularity
- Block-level: compress a whole block of tuples as a block, which uses a general-purpose algorithm, and it doesn't provide powerful compression (Zstd is most used).
- Tuple-level: compress the tuple itself (NSM)
- Attribute-level: compress single/many attributes inside the tuple (some others may not be compressed)
- Column-level: compress multiple values of the attribute altogether (DSM)
Columnar Compression
This is the most powerful compression, that's why it will be described in detail.
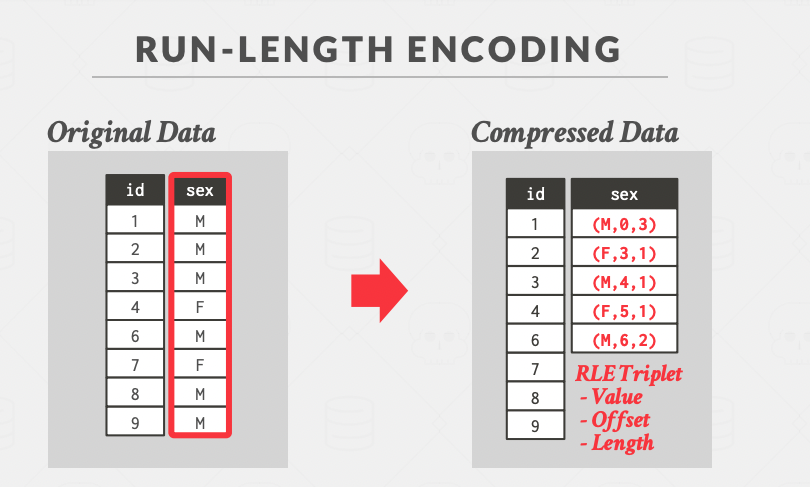
- Run-Length encoding: compress continuous occurrences of the same value in a single triplet (value, start position, length), and it requires the columns to be sorted in order to maximize the compression.
 If it was stored in sorted order, we could have achieved better compression:
If it was stored in sorted order, we could have achieved better compression:
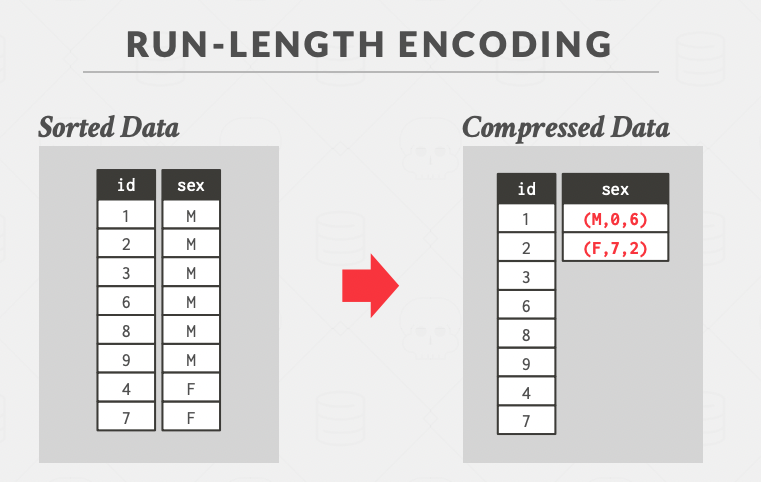
Side note: we can get rid of length, and calculate it from the start of the next triplet
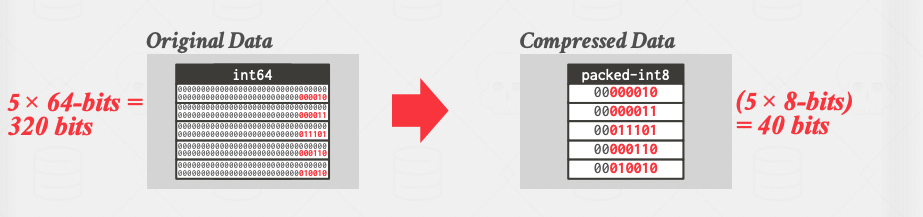
- Bit-Packing encoding: When the values of the attributes are always less than the largest size of the attribute, cast them to a smaller data type
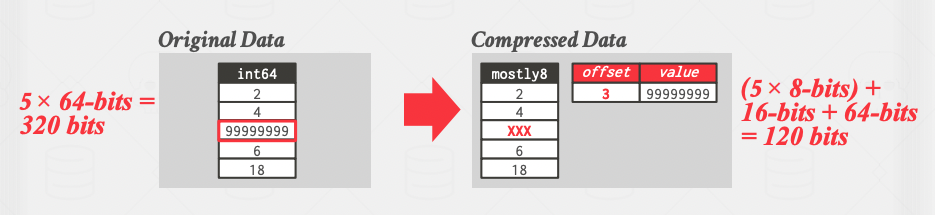
- Mostly encoding: The same as bit-packing encoding, but it handles the case that some values don't fit in the smaller data type, by creating a lookup table for those overflows.
- Bitmap encoding: Store a separate bitmap for each unique value of the attribute, and represent the i position in the bitmap with the value
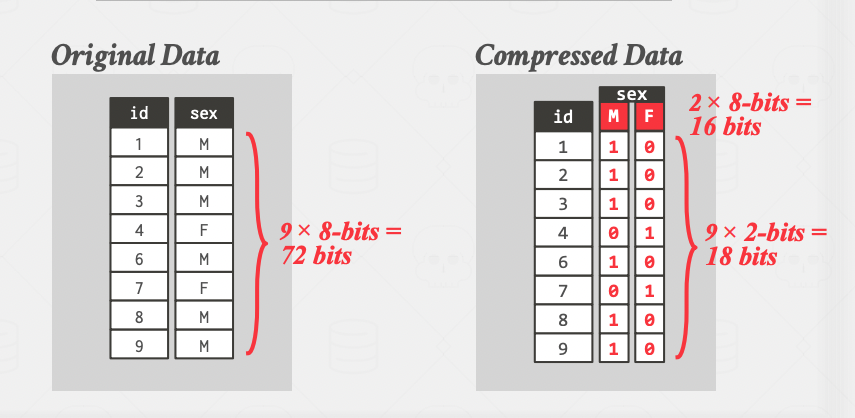
However, if the cardinality of the attribute is not low enough, we can get worse results than not using compression at all!

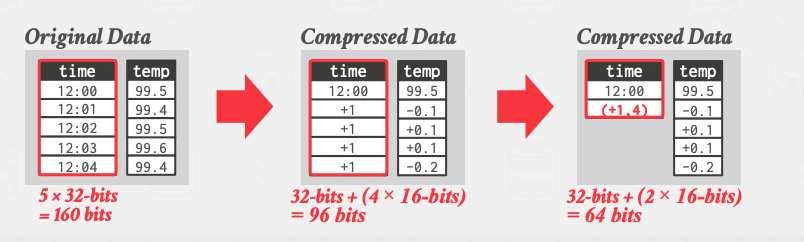
- Delta encoding: In this encoding method, we only store the difference between values following each other (we should store the base value). This method can be used along with Run-Length encoding to store the deltas in triplets.
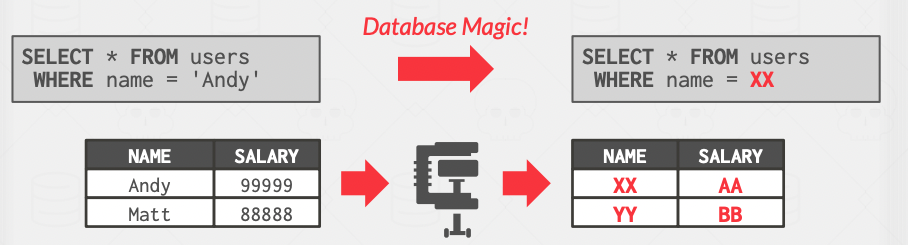
- Dictionary: Replace the actual long values with values that are less in size, similar to hashing, but we can not use hashing because we want a way to decompress it, and also we want to support range queries.

Postpone decompression
As said earlier, if we are going to use compression, it's better to postpone decompression as long as we can during query execution. Supporting operations on compressed data reduces the amount of memory required for doing such operations, however, DB engine should decompress data before returning it to the client.
References
- CMU15-445/645 Database Systems lecture notes. Retrieved from: 15445.courses.cs.cmu.edu/fall2022
- Database Internals: A Deep Dive into How Distributed Data Systems Work 1st Edition




