Database Buffer Pool - Part 1

A software engineer who is enthusiast about back-end engineering and system design with a flexible mindset. I love playing with frameworks and moving between the languages just like an artist playing
Introduction
In order to allow the database execution engine to perform its operations, it needs the pages containing the table records to be brought from disk to memory. However, we want to optimize I/O operations, so there is a subsystem of the database that handles this part, which is called Buffer Pool.
Components of the buffer pool
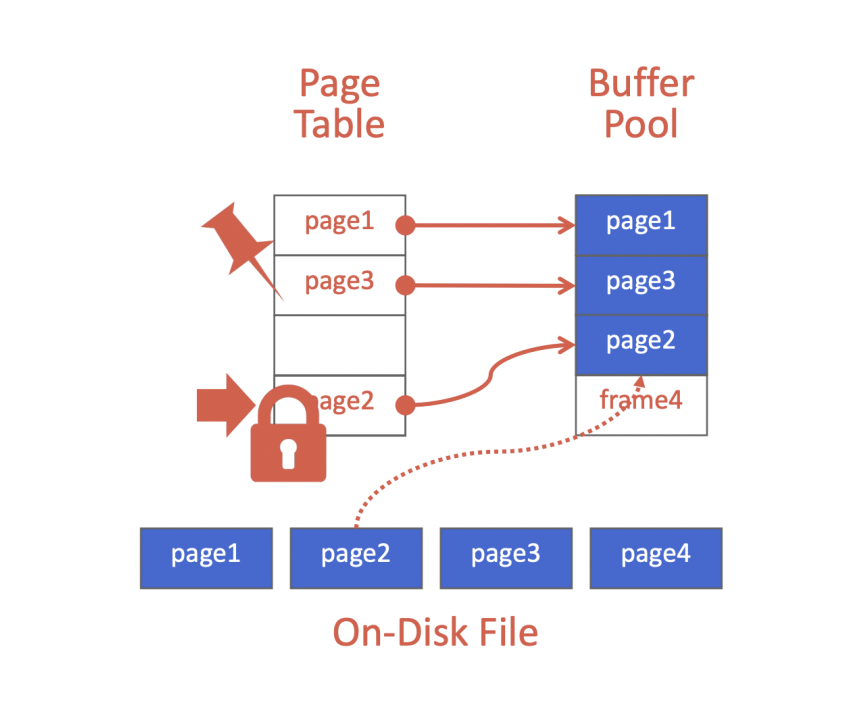
A buffer pool is no more than a large chunk of memory, allocated from the database engine memory, that's specified for handling storage requests from other parts of the system. It's usually an array of fixed-size entries, which are called frames. Also, the buffer pool contains a page table, which is another memory used to map page ids to the frames containing it, along with metadata about those frames, this metadata can help overcome concurrency challenges (dirty-flag for pages that needs to be written into disk, pin for shared thread accessing to prevent evicting page while being in use by another thread).
Different memory allocation policies
- Global policies: in those policies, the buffer pool cares about benefiting the entire workload under execution, it considers all active transactions to find the optimal memory allocation.
- Local policies: in those policies, the buffer pool tries to make a single transaction run faster, even if it's not the best for the overall workload.
Most open-source systems use both of those policies to achieve their goals
Buffer pool optimizations
There are different techniques that are used to optimize buffer pool performance and make sure it fulfills the requirements of the workload.
1- Multiple buffer pools
In this case, the main advantage is to reduce the latch contention, while improving the locality of the cache, by creating multiple buffer pools to support the execution of different usages. We can use different buffer pools for different databases or based on the type of page (different tables). The main advantage is to reduce the latch contention while improving the locality of the cache. Finding the correct buffer pool for each page can be done using either: embedding it inside the object id, or hashing the page id to get the buffer pool id.
2- Pre-fetching
When the query plan is ready, the first set of pages is processed, buffer pool can start fetching the next set of pages before it's already requested from it. This technique is helpful in the case of sequential scans.
3- Scan sharing (Synchornized-scans)
Different queries can re-use the pages retrieved from the disk, by allowing them to attach to a single cursor that's processing the table.
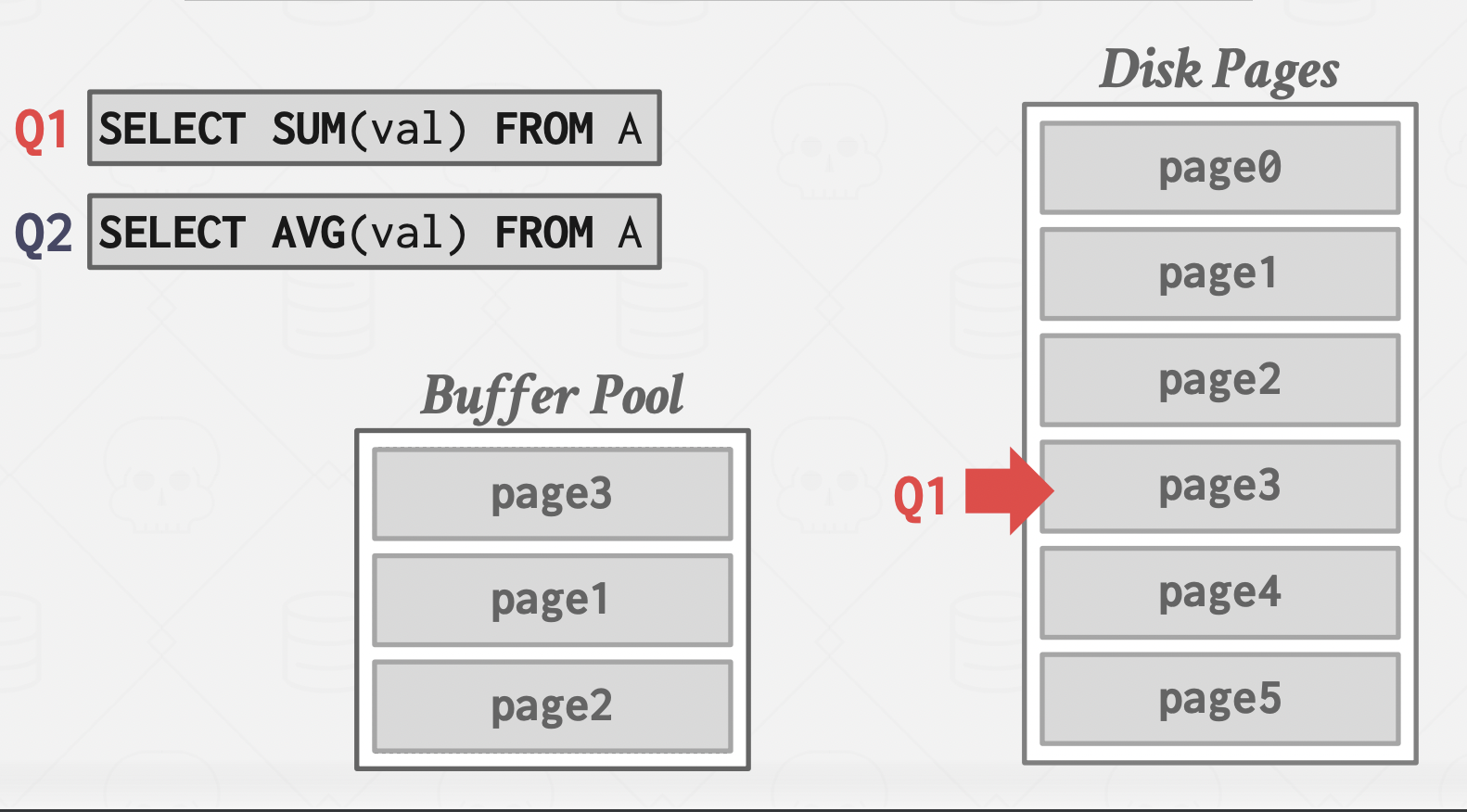 In this case, Q1 already processed pages: 0, 1, 2, and it's currently on 3, however, another query Q2 needs the same pages, database management system attaches the Q2 cursor to the Q1 cursor and makes it start processing from page 3, and so on until it finished Q1 cursor
In this case, Q1 already processed pages: 0, 1, 2, and it's currently on 3, however, another query Q2 needs the same pages, database management system attaches the Q2 cursor to the Q1 cursor and makes it start processing from page 3, and so on until it finished Q1 cursor
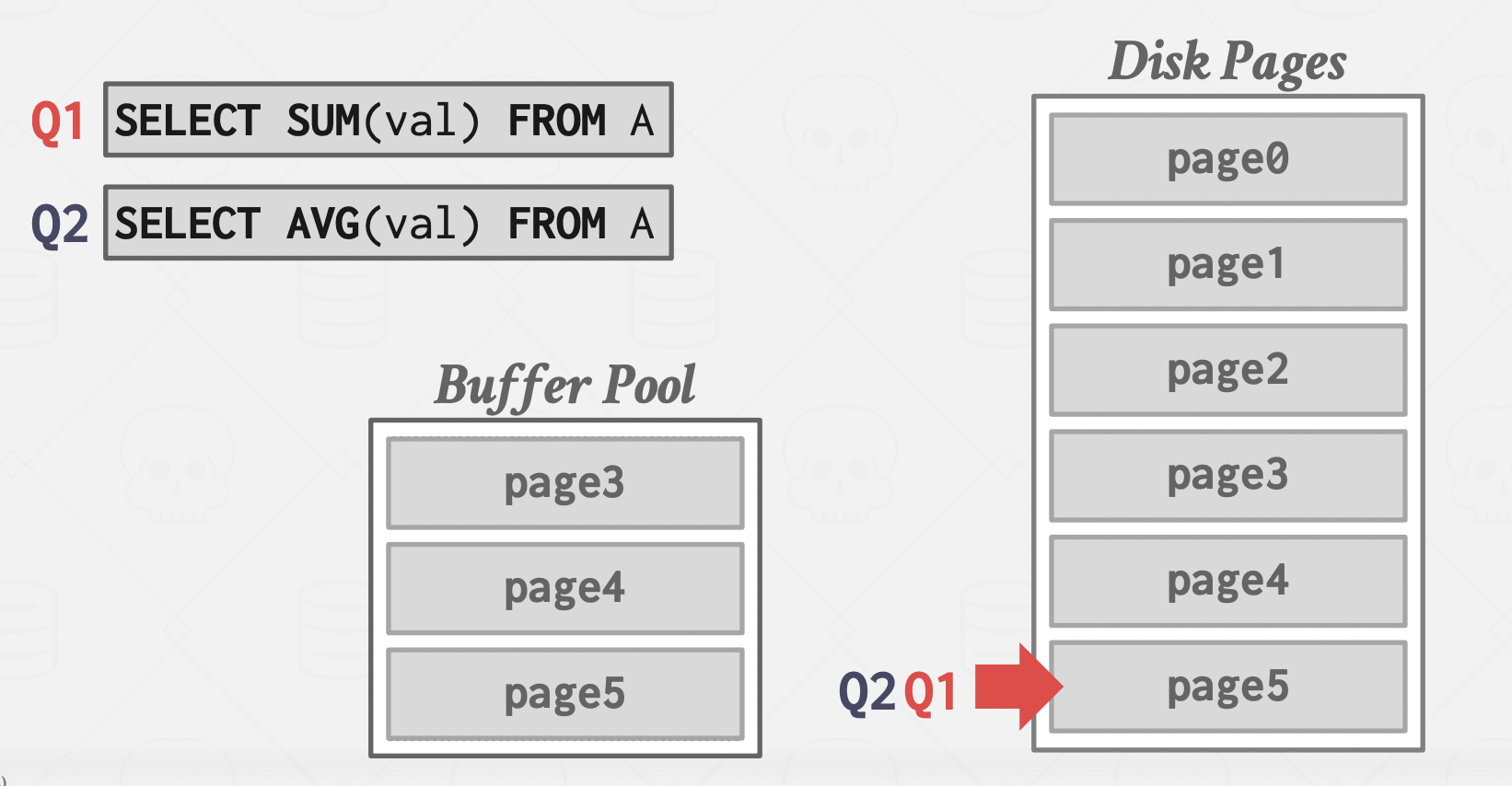 After that, it goes back to the pages that were not covered (0, 1, 2 in this case), and it continues processing them.
After that, it goes back to the pages that were not covered (0, 1, 2 in this case), and it continues processing them.
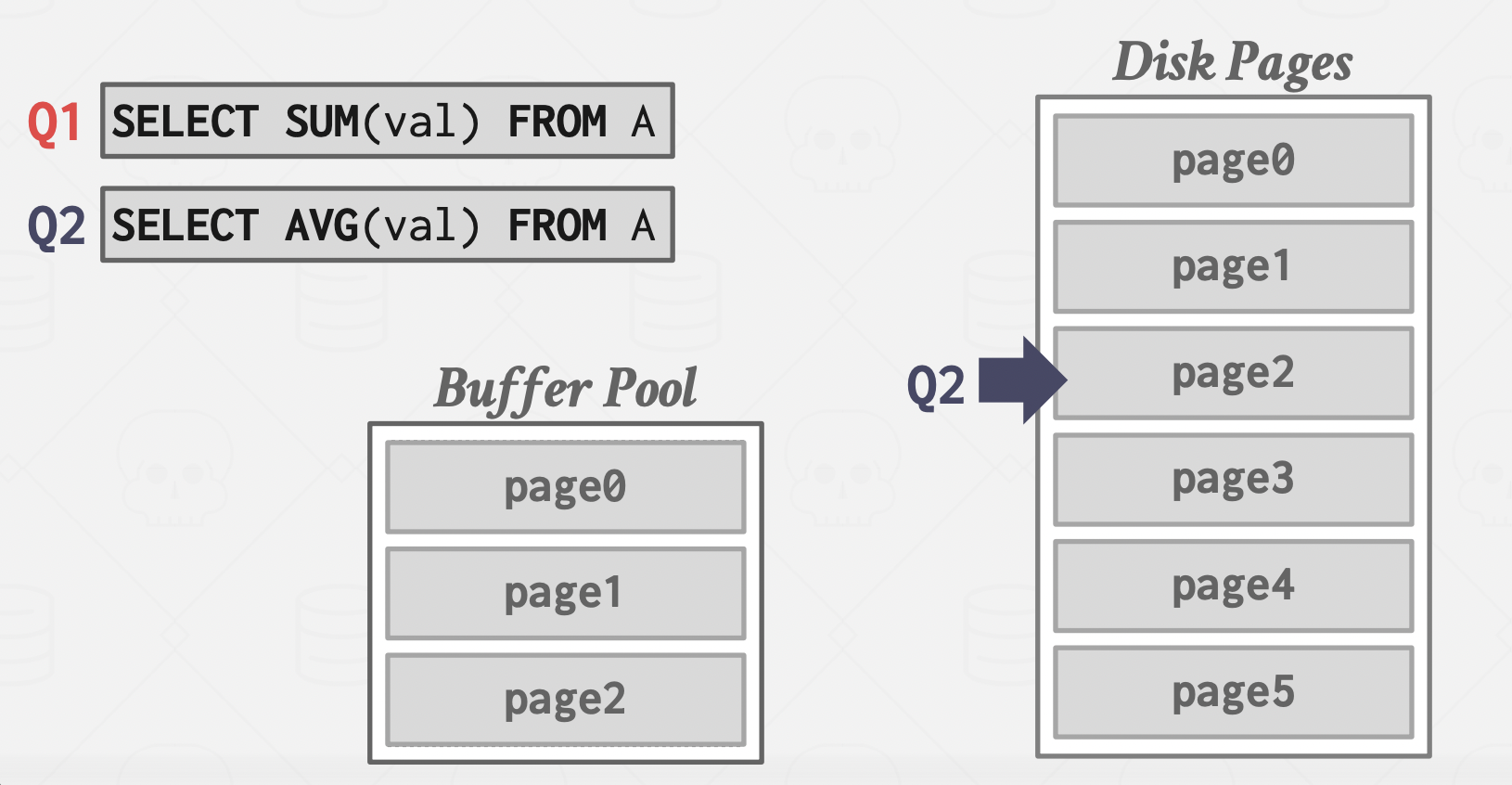 Pitfall: if Q2 is using LIMIT, the order of processing pages matters, but since our DBMS uses the relational model, no order is guaranteed, so it's not handled by the DBMS, which explains why we may get different results by running the same query with LIMIT.
Pitfall: if Q2 is using LIMIT, the order of processing pages matters, but since our DBMS uses the relational model, no order is guaranteed, so it's not handled by the DBMS, which explains why we may get different results by running the same query with LIMIT.
4- Buffer pool bypass
In the case of a sequential scan on a huge table, it's more convincing not to overwhelm the shared buffer pool with those pages, instead, DBMS allocates local memory for this long-running query. This technique works well if data is stored contiguously. Also, it's suitable for temporary data that are used for sorting for example.
References
- CMU15-445/645 Database Systems lecture notes. Retrieved from: 15445.courses.cs.cmu.edu/fall2022




